単音オーディオからMIDIへの変換器:オンセット検出、ピッチ推定、文字起こし
2025年8月10日
概要
オーディオをMIDIデータに変換することは、音楽技術において基本的な作業であり、演奏の解析、編集、合成を可能にします。複数の和音や重なる音符が存在するポリフォニックオーディオ検出とは異なり、単音オーディオ検出はより単純な信号を扱い、信号処理技術を用いてより正確な表現を実現できます。
本プロジェクトでは、単音のメロディー(同時に1つの音のみが鳴る)をMIDIに変換するシステムの構築に焦点を当てています。まずメロディーのオンセット時間を検出し、その各オンセットフレームに対してピッチを推定します。最後に、検出したオンセット時間とピッチ情報を組み合わせてMIDI表現を作成します。
なお、ノートの強さ(ベロシティ)やノートオフセット(音の終了時間)は固定値で割り当てています。
オンセット検出
最初のステップはオンセット検出です。これは各音符が始まる時間を決定する工程です。通常、音符の発音はオンセット(開始)、アタック、ディケイのフェーズで構成されます。本プロジェクトでは、ピアノとオーボエの録音を用いて、エネルギーベースの閾値処理やスペクトルフラックスなどの古典的な手法を試しました。
楽器によってパラメータを調整しています。ピアノはオンセットやアタックが鋭くはっきりしているのに対し、オーボエは一般的に穏やかでゆるやかです。エネルギーベースの閾値処理とスペクトルフラックスの両方が十分なパラメータ調整により使用可能な結果を出しましたが、最終的にはスペクトルフラックスの方がより良く、信頼性の高いオンセット検出となりました。
以下の図は、ピアノとオーボエのスペクトルフラックスによるオンセット検出の様子と、それに対応したオンセットタップ付きのオーディオサンプルを示しています。
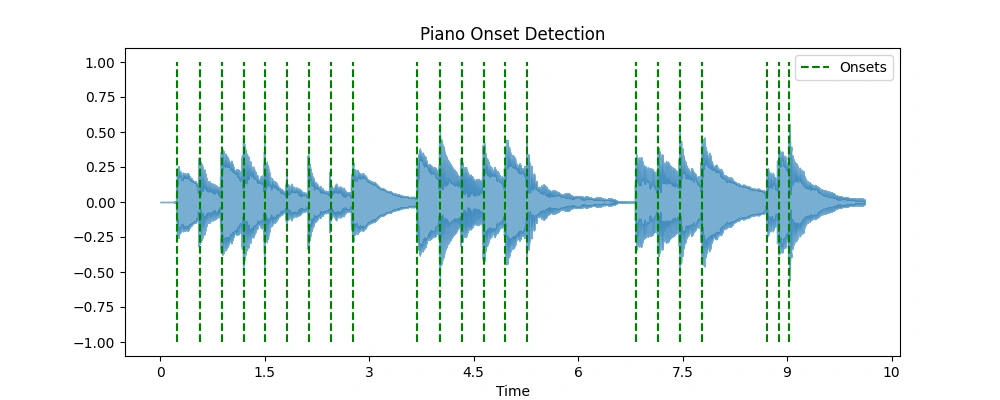 ピアノのオンセット検出図
ピアノのオンセット検出図
ピアノの入力オーディオ
 オーボエのオンセット検出図
オーボエのオンセット検出図
オーボエの入力オーディオ
ピッチ検出
ノートの開始時間が特定された後(前節のオンセット検出参照)、次はピッチ推定です。ここではよく知られた二つのピッチ検出アルゴリズム、YIN と PYIN を実装し比較しています。
評価のため、単音メロディの一部分に対して文字起こしパイプラインを動作させました。以下はYINアルゴリズムの差分関数と累積平均正規化差分関数のプロットです。
 YINピッチグラフ
YINピッチグラフ
YINアルゴリズム
ステップ1: 差分関数
長さ $W$ の音声フレーム $x[n]$ に対し、差分関数 $d(\tau)$ はラグ $\tau$ だけ遅延させた信号との二乗差を計算します:
$$ d(\tau) = \sum_{n=0}^{W-\tau-1} \big( x[n] - x[n+\tau] \big)^2 $$
変数の説明:
- $x[n]$:インデックス $n$ の音声サンプル
- $W$:現在のフレームの総サンプル数(フレーム長)
- $\tau$:ラグ(遅延)パラメータ、候補となる基本周期を示す
ステップ2: 累積平均正規化差分関数(CMND)
累積平均正規化差分関数 $\text{cmnd}(\tau)$ は $d(\tau)$ を正規化し、基本周期の検出を容易にします:
$$ \text{cmnd}(\tau) = \begin{cases} 1, & \tau = 0, \ \dfrac{d(\tau)}{\frac{1}{\tau} \sum_{j=1}^{\tau} d(j)}, & \tau > 0 \end{cases} $$
変数の説明:
- $d(\tau)$:ステップ1の差分関数
- $\tau$:ラグ値
ステップ3: 基本周期の候補検出(絶対閾値)
探索範囲 $[\tau_{\min}, \tau_{\max}]$ の中で、正規化差分が閾値以下となる最小のラグ $\tau$ を基本周期の候補として選びます:
$$ \text{cmnd}(\tau) < \text{threshold} $$
探索範囲は検出対象の周波数範囲から決まります:
$$ \tau_{\min} = \frac{f_s}{f_{\max}}, \quad \tau_{\max} = \frac{f_s}{f_{\min}} $$
変数の説明:
- $f_s$:サンプリング周波数(Hz)
- $f_{\min}, f_{\max}$:検出対象の最小・最大基本周波数(Hz)
- $\text{threshold}$:閾値(例:0.1~0.2)
ステップ4: 基本周波数の推定
候補ラグ $\tau_{\text{est}}$ が決定されたら、基本周波数 $f_0$ は以下で計算されます:
$$ f_0 = \frac{f_s}{\tau_{\text{est}}} $$
変数の説明:
- $\tau_{\text{est}}$:推定された基本周期のラグ
- $f_0$:推定基本周波数(Hz)
PYINアルゴリズムは、YINの確定的推定を拡張し、確率的アプローチを用いてピッチ追跡の精度を大幅に向上させています。単一のフレームに対し複数のピッチ候補を生成し、それぞれに候補の妥当性を示す確率を割り当てます。これらの候補は累積平均正規化差分やエネルギーなどの音響特徴量に基づいています。
特にPYINの強みは、時間的に連続したピッチの自然な変化をモデル化することにあります。ピッチが連続するフレーム間でどれだけ安定的または滑らかに変化するかを遷移確率として組み込み、急激な大きなピッチ変化が稀であることを反映しています。
最適なピッチ経路を決定するために、動的計画法の一種であるビタビアルゴリズムを用いて、音声全体の全候補ピッチから最も確率の高い経路を効率的に探索します。これにより、フレーム単位での独立解析で生じるノイズや不連続性が低減され、滑らかで自然なピッチ追跡が実現します。
また、各フレームが有声音か無声音かを同時に判定し、難しい環境下でも頑健な結果が得られます。
以下はオーボエのメロディの最初の区間におけるPYINのピッチ候補と、ビタビで復号した最終ピッチトラックのプロットです。
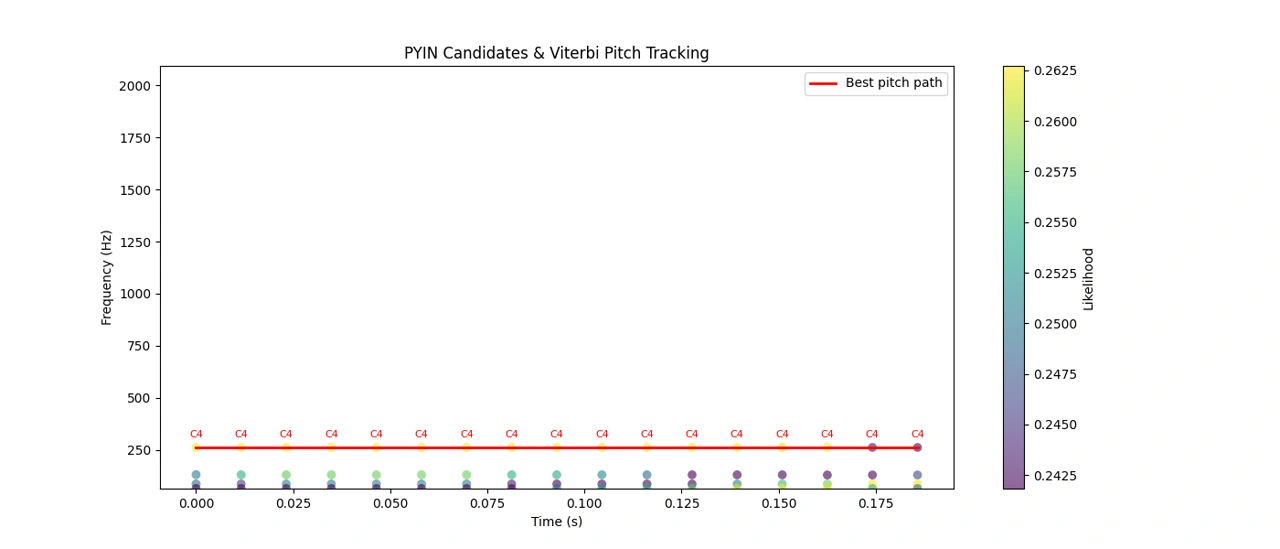 PYINとビタビのピッチ追跡
PYINとビタビのピッチ追跡
アルゴリズム
オーディオの読み込み
処理のために音声信号を読み込みます。時間-周波数表現の計算
短時間フーリエ変換(STFT)を用いて時間領域信号を時間-周波数表現に変換します。STFTは線形周波数ビンを生成し、一般的なスペクトル変化の解析に適しています。大きさスペクトルを用いたオンセット検出
- エネルギーベース手法: スペクトルを循環シフトして隣接フレームのエネルギー差を計算し、中央値に基づく閾値でオンセットを検出。
- スペクトルフラックス: フレーム間のスペクトル振幅の正の増加を測定し、ピークがオンセットに対応。
検出された各オンセットでのピッチ推定
各オンセット後の短時間区間(通常40~100ms)を分析し、ノートの初期安定音を捉えます。- YINアルゴリズム: 自己相関の差分関数を用いた基本周波数推定。
- PYINアルゴリズム: YINを拡張した確率的な手法で、より滑らかで頑健なピッチ追跡を実現。
ノートデータの保存
ノートの開始時間(オンセット)、推定終了時間(次のオンセットや固定時間)、ピッチ周波数を記録。- ベロシティ: オンセットのエネルギーや振幅から推定、または固定値割り当て。ノートの強さや終了時間は簡易のため固定値とすることが多い。
MIDIの出力と合成
抽出したノート情報をMIDIファイルに変換し、必要に応じて音声合成を行う。
パラメータ
| パラメータ | 説明 | 代表的な値 |
|---|---|---|
frame_length |
STFTやピッチ解析のウィンドウサイズ | 2048サンプル |
hop_length |
解析フレーム間のステップサイズ | 256サンプル |
fmin |
ピッチ検出の最小周波数 | 約27.5 Hz(A0) |
fmax |
ピッチ検出の最大周波数 | 約4186 Hz(C8) |
delta |
スペクトルフラックスによるオンセット検出の感度閾値 | 0.12(小さいほど感度が高い) |
min_note_gap |
ノートの最小持続時間 | 0.05秒 |
tentative_end_gap |
次のオンセットまでのノート終了判定ギャップ | 0.02秒 |
コード例(Python)
import librosa
import numpy as np
import pretty_midi
from energyOnset import spectral_energy_onset_detect
def extract_midi_from_audio(audio_path, onset_method='spectral-flux',
pitch_method='yin'):
# Parameters
hop_length = 256
frame_length = 2048
fmin = librosa.note_to_hz('A0') # Minimum pitch frequency
fmax = librosa.note_to_hz('C7') # Maximum pitch frequency
# Load audio
y, sr = librosa.load(audio_path)
# Onset detection
if onset_method == 'energy':
onset_frames, onset_times = spectral_energy_onset_detect(y, sr)
else: # Default: spectral-flux method
onset_frames = librosa.onset.onset_detect(
y=y,
sr=sr,
hop_length=hop_length,
pre_max=5,
post_max=5,
pre_avg=5,
post_avg=5,
delta=0.12, # smaller delta for higher sensitivity
wait=2
)
onset_times = librosa.frames_to_time(
onset_frames, sr=sr, hop_length=hop_length)
# Initialize PrettyMIDI and instrument
pm = pretty_midi.PrettyMIDI()
# Electric Piano by default
melody_instr = pretty_midi.Instrument(program=4)
# minimum duration of a note (seconds)
min_note_gap = 0.05
# Process each onset segment for pitch detection
for i, onset_frame in enumerate(onset_frames):
start_sample = onset_frame * hop_length
end_sample = (onset_frames[i + 1] * hop_length
if i + 1 < len(onset_frames) else len(y))
segment = y[start_sample:end_sample]
# Skip segment if too short for pitch analysis
if len(segment) < frame_length:
continue
# Pitch detection
if pitch_method == 'pyin':
f0_est, voiced_flag, _ = librosa.pyin(
segment,
fmin=fmin,
fmax=fmax,
sr=sr,
frame_length=frame_length,
hop_length=hop_length,
fill_na=np.nan,
center=False
)
else: # Default pitch detection using YIN
f0_est = librosa.yin(
segment,
fmin=fmin,
fmax=fmax,
sr=sr,
frame_length=frame_length,
hop_length=hop_length,
trough_threshold=0.05,
center=False
)
# Convert detected frequencies to MIDI note numbers
f0_est_midi = librosa.hz_to_midi(f0_est)
valid_pitches = f0_est_midi[~np.isnan(f0_est_midi)]
if len(valid_pitches) == 0:
continue
# Use median pitch as primary note for the segment
primary_pitch = int(round(np.median(valid_pitches)))
# MIDI note range A0 (21) to C8 (108)
primary_pitch = np.clip(primary_pitch, 21, 108)
# Determine note timing with a small gap heuristic
start_time = onset_times[i]
if i + 1 < len(onset_times):
tentative_end = onset_times[i + 1] - 0.02
else:
tentative_end = start_time + 0.2
end_time = max(start_time + min_note_gap, tentative_end)
# Append the note to the instrument
melody_instr.notes.append(
pretty_midi.Note(
velocity=80,
pitch=primary_pitch,
start=start_time,
end=end_time
)
)
# Add instrument to PrettyMIDI object
pm.instruments.append(melody_instr)
return pm
if __name__ == "__main__":
# Extract and save MIDI from oboe audio
pm = extract_midi_from_audio(
"melody-oboe-trimmed.mp3",
onset_method='spectral-flux',
pitch_method='pyin'
)
pm.write("output-oboe.mid")出力結果
オーボエとピアノのメロディに対してコードを実行したところ、驚くほど良好な結果が得られました。
ピアノに比べてオーボエのメロディはパラメータ調整にやや時間を要しましたが、耳で聴いた限り文字起こしの精度はかなり高いと感じられました。
以下に入力音声と出力音声の比較を示します。
ピアノの入力メロディ
ピアノの文字起こし出力メロディ
オーボエの入力メロディ
オーボエの文字起こし出力メロディ